Why Your Enterprise AI Strategy Needs an Orchestration Layer
The tool is not the problem. The integration is.
Most enterprises evaluating AI development tools hit the same wall. The technology works. The demos are impressive. But the conversation stalls at the same three questions:
- What happens when our preferred AI vendor changes pricing, or gets acquired, or degrades?
- Can we run this on our own infrastructure without sending proprietary code to external APIs?
- How do we prove to auditors exactly what the AI did, when, and who approved it?
These are not hypothetical concerns. They are the reason most AI adoption stalls between "successful pilot" and "enterprise rollout." The gap is not capability. It is architecture.
This post explains how Operum addresses each of these blockers — not by being another AI coding tool, but by being the orchestration layer that sits above them.
What Operum actually is
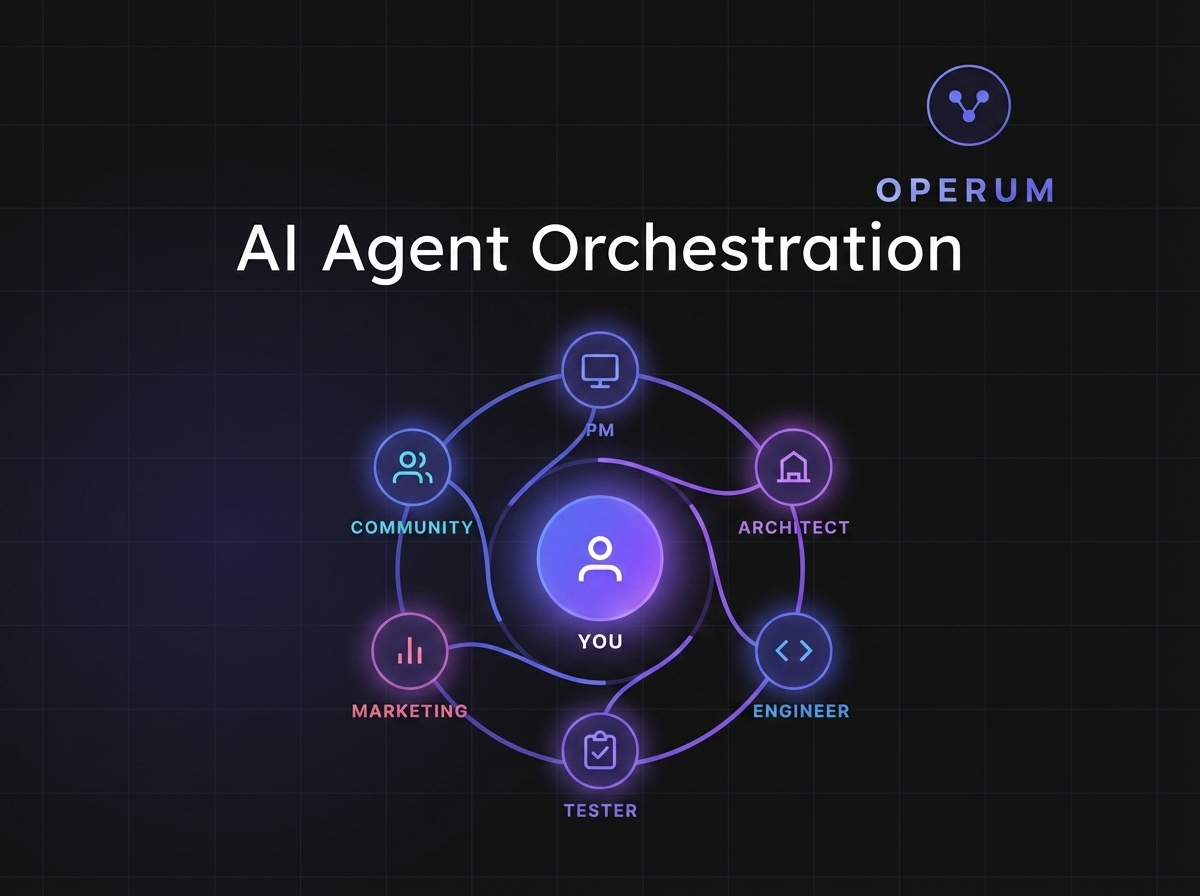
Operum is an AI agent orchestration platform. It coordinates six specialized agents — PM, Architect, Engineer, Tester, Marketing, and Community — to manage software development workflows end to end. Think of it as a project manager for AI agents: it assigns work, routes decisions, enforces approvals, and keeps humans in the loop.
The agents do not operate in a black box. Every action flows through your existing version control system, every decision is logged, and every merge requires human approval. Operum is the coordination layer between your AI tools and your development process.
What makes the architecture enterprise-ready is not the agents themselves. It is the three layers underneath them.
1. Pluggable AI Engines: Zero Vendor Lock-In
Here is the reality of the AI landscape in 2026: no single provider is best at everything. Claude excels at reasoning and architectural analysis. GPT models are fast at code generation. Cursor's integration with your editor is unmatched for inline work. Local models give you data sovereignty.
Operum does not force a choice. Its AI Engine architecture lets you connect any backend to any agent:
| Agent | Engine Option A | Engine Option B | Engine Option C |
|---|---|---|---|
| PM Agent | Claude Code | OpenAI | Local (Ollama) |
| Architect | Claude Code | Cursor | Local (Ollama) |
| Engineer | Cursor | GitHub Copilot | Local (Ollama) |
| Tester | Claude Code | Cursor | Local (Ollama) |
Each agent can run on a different engine. You can assign Claude to your Architect for its reasoning depth, Cursor to your Engineer for its code generation speed, and a local model to your Tester for cost efficiency.
Why this matters for enterprises:
- No vendor lock-in. If OpenAI changes pricing tomorrow, you swap the engine — not the platform. Your workflows, your agent configurations, your approval chains, your audit logs all stay intact.
- Best-of-breed selection. Different tasks have different requirements. Architecture review needs deep reasoning. Code generation needs speed. Testing needs thoroughness. Match the model to the job.
- Gradual migration. Start with cloud APIs for evaluation. Move sensitive workloads to local inference when ready. No rearchitecting required.
- Procurement flexibility. Legal approved Anthropic but not OpenAI? Use Claude. IT standardized on Azure? Use Azure OpenAI. The orchestration layer adapts to your constraints.
2. Local Inference and Data Sovereignty
For regulated industries — finance, healthcare, defense, legal — the question is not "is AI useful?" It is "can we use it without sending proprietary code to a third-party API?"
Operum's upcoming LocalEngine support answers this directly. With Ollama integration, organizations running GPU machines (48GB+ VRAM) can power their agents entirely on-premise:
- Zero data egress. Your code never leaves your network. Not for training, not for inference, not for logging.
- Zero API costs. After the initial hardware investment, inference is free. For teams running hundreds of agent tasks per day, this changes the unit economics entirely.
- Full compliance control. Your security team controls the model weights, the inference environment, and the data retention policy. No third-party processing agreements required.
- Air-gapped deployment. For defense and classified work: disconnect from the internet entirely. The agents run on your hardware, your models, your network.
The architecture does not force an either-or choice. You can run your PM agent on Claude (where reasoning quality matters most and the data is non-sensitive task descriptions) while running your Engineer agent on a local model (where the code itself is processed). Sensitive data stays local. Non-sensitive coordination uses the best cloud model available.
3. Full Transparency Audit Trail
This is where most AI tools fail the enterprise evaluation. They produce output, but they cannot explain how they got there. When your compliance team asks "what did the AI do to our codebase last Tuesday at 3pm, and who approved it?" — most tools have no answer.
Operum logs everything:
- What was done: Every file change, every PR created, every test run, every issue triaged.
- Why it was done: The agent's reasoning is captured — which issue it was responding to, which architectural guidance it followed, which previous review comments it addressed.
- Which agent did it: PM, Architect, Engineer, Tester — each action is attributed to the specific agent role.
- Which AI model powered it: "Engineer agent, running on Claude 4.5, processed issue #412." The model version is logged alongside every action.
- Who approved it: Every merge, every deployment, every publish action includes the human approver's identity and timestamp.
This is not optional logging you have to configure. It is the native behavior of the platform. Every action flows through your version control system as comments, labels, and commits — creating an audit trail that your existing compliance tools can already parse.
For SOC 2 and governance:
- Complete chain of custody from issue creation to deployed code
- Clear separation between AI-generated actions and human approvals
- Model versioning ensures reproducibility — you know exactly which AI version produced which output
- All logs live in your GitHub repository, not in a third-party system
4. Issue Tracker Flexibility
Enterprises do not start from scratch. They have Jira boards with three years of history. They have Linear workflows their teams spent months configuring. They have Azure DevOps pipelines integrated with their CI/CD.
Operum uses GitHub Issues today (see our integrations roadmap), but the architecture is designed for integration with any issue tracking system. The agent coordination layer speaks in terms of tasks, statuses, and transitions — not GitHub-specific APIs. This means the path to Jira integration, Linear integration, or Azure DevOps integration is an adapter, not a rewrite.
For enterprises evaluating the platform today:
- GitHub-native organizations can deploy immediately with full functionality.
- Jira/Linear shops can run Operum alongside their existing tracker during evaluation, with deeper integration on the roadmap.
- The investment is protected because the workflow logic, agent configurations, and audit logs are decoupled from the issue tracker.
5. Business-Friendly Interface
Operum's interface speaks in business terms, not developer jargon. What was "Pipeline" is now "Workflow." What was "CI/CD" is now "Automated Checks." Inline agent configuration lets managers adjust agent behavior without touching configuration files.
This matters for enterprise adoption because the people who approve AI tool purchases are often not the people who use them daily. When a VP of Engineering sees a clean dashboard with "Workflows," "Review Requests," and "Automated Checks" — rather than "Pipelines," "Pull Requests," and "CI/CD" — the tool sells itself.
The goal is not to hide complexity. It is to present it in terms that every stakeholder understands. The engineer sees the same data as the CTO — just through a lens appropriate to their role.
The enterprise evaluation checklist
If you are evaluating AI development tools for your organization, here is what to ask:
| Question | Why It Matters |
|---|---|
| Can we swap AI providers without rearchitecting? | Vendor risk mitigation |
| Can we run inference on our own infrastructure? | Data sovereignty, compliance |
| Is every AI action logged with model version and human approver? | Audit, SOC 2, governance |
| Does it integrate with our existing issue tracker? | Adoption friction |
| Can non-technical stakeholders understand the interface? | Organizational buy-in |
| Does the vendor lock our data into their platform? | Exit strategy |
Operum answers "yes" to each of these — not because we designed for a checklist, but because these are the real requirements that emerged from building an AI orchestration platform for production use.
Try it
Operum is free during public beta. It runs as a desktop application — your code stays on your machine, your infrastructure, your terms.
For enterprise teams evaluating AI adoption: this is the lowest-friction way to see what multi-agent orchestration looks like in practice. Download the app, connect a repository, configure your preferred AI engines, and watch six agents coordinate your development workflow.
- Website: operum.ai
- GitHub: alprimak/operum
- Discord: Join the community
For enterprise inquiries, custom deployments, or compliance-specific questions — reach out directly through the website.
The AI tool market solved generation. Operum solves orchestration.
Related Posts
- Building an AI Agent Orchestrator: How 6 Agents Coordinate Through GitHub — The technical architecture behind multi-agent coordination.
- Why "Never Loses Context" Changes Everything — How persistent context makes AI agents compound intelligence over time.
- The AI Tools Landscape in 2026 — Where every AI tool converges, and why orchestration is the missing layer.