Why "Never Loses Context" Changes Everything for AI-Powered Development
You have had this conversation before
It is Monday morning. You open your AI coding assistant. You type something like:
"Can you help me refactor the authentication module?"
And then it happens. The blank stare. The polite but devastating response:
"Sure! Could you tell me more about your project? What framework are you using? What does your current authentication module look like?"
You explained all of this on Friday. You walked it through your entire codebase. You described the architecture, the edge cases, the reason you chose Supabase over Auth0, the bug in the session refresh logic that took you three hours to find. All of that is gone. Every single session, you start from zero.
If you are a developer or a startup founder who has spent real time with AI coding tools, you know this feeling. It is not a minor inconvenience. It is a fundamental broken promise. The tool that was supposed to save you time now costs you twenty minutes of re-explanation before it can do anything useful.
This is the context problem. And it changes everything about whether AI tools actually deliver on their promise.
The context window is not context
Most AI tools today operate within a context window — a fixed amount of text the model can "see" at any given moment. Modern models have large windows. Some can hold 100,000 tokens or more. That sounds like a lot.
It is not.
A medium-sized codebase — the kind a startup founder works with daily — can easily exceed a million tokens. Your README, your configuration files, your database schema, your API routes, your frontend components, your test suites, the architectural decisions you made six months ago, the bug you fixed last Tuesday. None of this fits in a single context window, and even if portions of it did, it all disappears the moment your session ends.
Context windows are short-term memory. What developers actually need is long-term memory.
The difference matters. Short-term memory lets an AI tool understand the code you paste into the chat right now. Long-term memory lets it understand why your team chose a specific database, what your deployment pipeline looks like, which modules are fragile, and what "done" looks like for your project. Short-term memory answers questions. Long-term memory makes good decisions.
What "losing context" actually costs you
The cost is not just the twenty minutes of re-explanation. That is the visible tax. The invisible tax is worse.
You simplify your requests. Instead of asking the AI to "refactor the payment flow to handle the new subscription tiers we discussed," you ask it to "refactor this function." You strip out the context because you know it will not remember. You get a simpler answer because you asked a simpler question.
You become the context bridge. In a team of AI agents — or even a single AI assistant used across different tasks — you are the one holding all the threads. The AI helped you design the API on Monday. On Tuesday, you ask it to write tests. But it does not know what it designed yesterday, so you re-explain the API. You become the messenger between an AI and itself.
You stop trusting it with complex work. After the fifth time re-explaining your architecture, you stop trying. You use the AI for autocomplete and boilerplate. The ambitious refactors, the cross-module changes, the architectural decisions — you go back to doing those yourself. The tool that promised to be a senior engineer becomes a glorified snippet generator.
You lose compounding intelligence. A human teammate who has worked on your project for three months is exponentially more useful than one who started today. They know the codebase, the conventions, the landmines. AI tools that reset every session never get past day one. They never compound. Every conversation is their first day on the job.
Persistent context is not a feature. It is the foundation.
When we built Operum, we made a decision early: context persistence would not be an add-on. It would be the architecture.
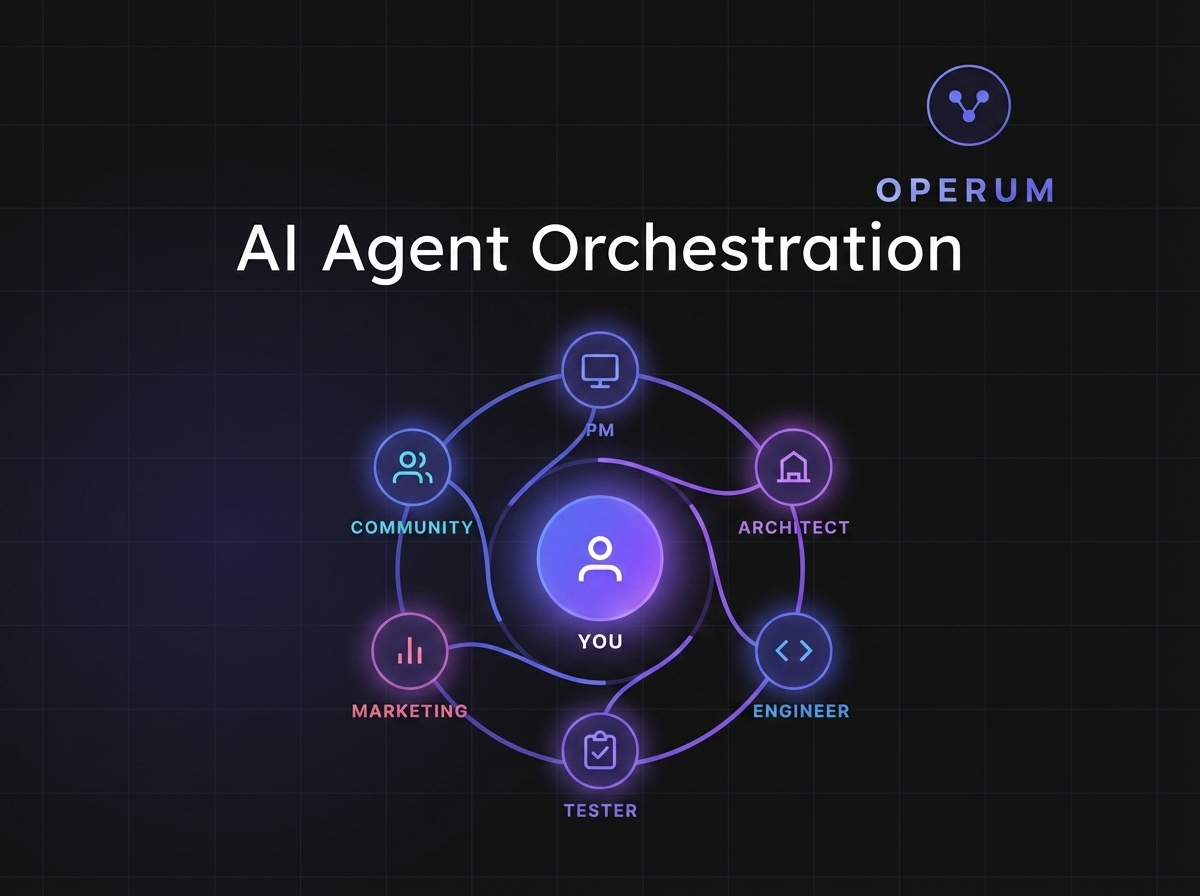
Every Operum agent — the Engineer, the Architect, the Tester, the Marketing Lead, the Community Manager, the Project Manager — operates from a shared, persistent knowledge base. This is not a chat history. It is structured project knowledge: architectural decisions, coding conventions, known issues, deployment procedures, team preferences, and the reasoning behind past choices.
When the Engineer creates a pull request, the Tester already knows the architecture because both agents read from the same knowledge base. When the Architect reviews a design, they know what was tried before and why it was rejected. When the Project Manager triages a bug, they know which modules are fragile and which developer conventions apply.
This is what persistent AI memory actually looks like in practice. Not a longer chat log. A shared brain that every agent reads from and writes to.
Shared knowledge changes the math on AI teams
Consider what happens when context is truly persistent and shared across a team of AI agents.
Day 1: You describe your project. The knowledge base captures your tech stack, your architecture, your conventions, your goals.
Week 1: The agents have handled several tasks. The knowledge base now includes architectural decisions, bug patterns, deployment notes, and your preferences for code style, PR format, and communication.
Month 1: The agents know your codebase as well as a human teammate who has been working on it full-time. They know which modules interact, where the technical debt lives, which tests are flaky, and what your definition of "production-ready" means.
Month 3: The knowledge base is a genuine institutional asset. It captures not just what your project is, but how it evolved, why decisions were made, and what the team has learned. A new human joining your team could read it and get up to speed faster than any onboarding document you have ever written.
This is compounding intelligence. Every task makes the system smarter about your specific project. Every decision adds to the shared context. The AI team that remembers is not just avoiding re-explanation — it is accumulating expertise.
The contrast with how AI tools work today
Today, if you use Claude Code, Copilot, Cursor, or Codex, each session is isolated. Some tools offer memory features — Claude Code has auto-memory, Copilot has custom instructions — but these are individual, surface-level, and scoped to a single tool.
None of them solve the core problem: multiple AI agents working on the same project with shared, deep, persistent understanding. (For a detailed comparison of what each tool does and does not do, see The AI Tools Landscape in 2026.)
Imagine a software company where every employee had amnesia at the end of each workday. Every morning, they walk in and ask: "What do we do here? What are we building? What did we decide yesterday?" You would not call that a team. You would call it a disaster.
That is how multi-tool AI workflows work today. Your coding AI does not know what your testing AI found. Your architecture tool does not know what your project management tool decided. You are the glue. You are the shared memory. And that defeats the entire purpose of having AI assistants.
What this means for startup founders
If you are a technical founder wearing five hats — and you are, because that is what early-stage startups require — persistent AI context retention is not a nice-to-have. It is the difference between AI tools that add cognitive load and an AI team that reduces it.
With persistent context:
- You stop repeating yourself. Describe your architecture once. The entire team knows it.
- You delegate confidently. Tell the PM to create a task. The Engineer picks it up with full context. The Tester reviews it knowing what was built and why.
- You get compounding returns. Month three is dramatically more productive than month one, because the team has accumulated real project knowledge.
- You focus on decisions, not explanations. Your role shifts from "person who re-explains everything to AI tools" to "person who makes strategic decisions while the AI team executes."
This is what we mean when we say Operum never loses context. It is not a marketing claim about memory features. It is an architectural commitment that every agent, every session, every task builds on everything that came before.
The gap nobody is filling
The AI tools landscape in 2026 is remarkable. There are tools that write code at near-human quality, tools that autocomplete faster than you can think, tools that spin up parallel agents on cloud VMs. The engineering capability is extraordinary.
But capability without continuity is just potential. A brilliant engineer who forgets everything they learned yesterday is not a senior engineer — they are an intern, every single day, forever.
The missing piece is not smarter models or larger context windows. It is persistent, shared, structured knowledge that turns a collection of AI tools into an actual team.
That is what "never loses context" means. And that is why it changes everything.
Operum is the AI team that remembers. Learn more at operum.ai
Related Posts
- Building an AI Agent Orchestrator: How 6 Agents Coordinate Through GitHub — The technical deep-dive on how these agents actually coordinate work.
- The AI Tools Landscape in 2026 — Seven tools, one gap — and why persistent context is the missing piece.
- Why Your Enterprise AI Strategy Needs an Orchestration Layer — How persistent context and audit trails meet enterprise requirements.